overview
A data science project exploring whether online media presence affects soccer team performance. We analyzed ~60 Premier League matches across five top teams (Arsenal, Liverpool, Manchester United, Manchester City, Chelsea) to determine if the number of news articles published between games could predict goals scored. Using Selenium web scraping for ESPN match data and The Guardian API for article counts, we built linear and polynomial regression models to test this hypothesis.
data pipeline
pd.read_html() on the page source.
content.guardianapis.com retrieve
articles matching team names within date ranges, returning headline, word count, and publication timestamp.
match window logic
The core challenge was attributing articles to the correct game. We defined a "match window" as the period between one game's end time and the next game's start time.
This approach captures the media narrative between matches: post-match analysis of Game N and preview coverage for Game N+1. The assumption is that this combined coverage could influence team morale, fan expectations, or perceived pressure.
machine learning
We tested whether article count (x) could predict goals scored (y) using two regression approaches:
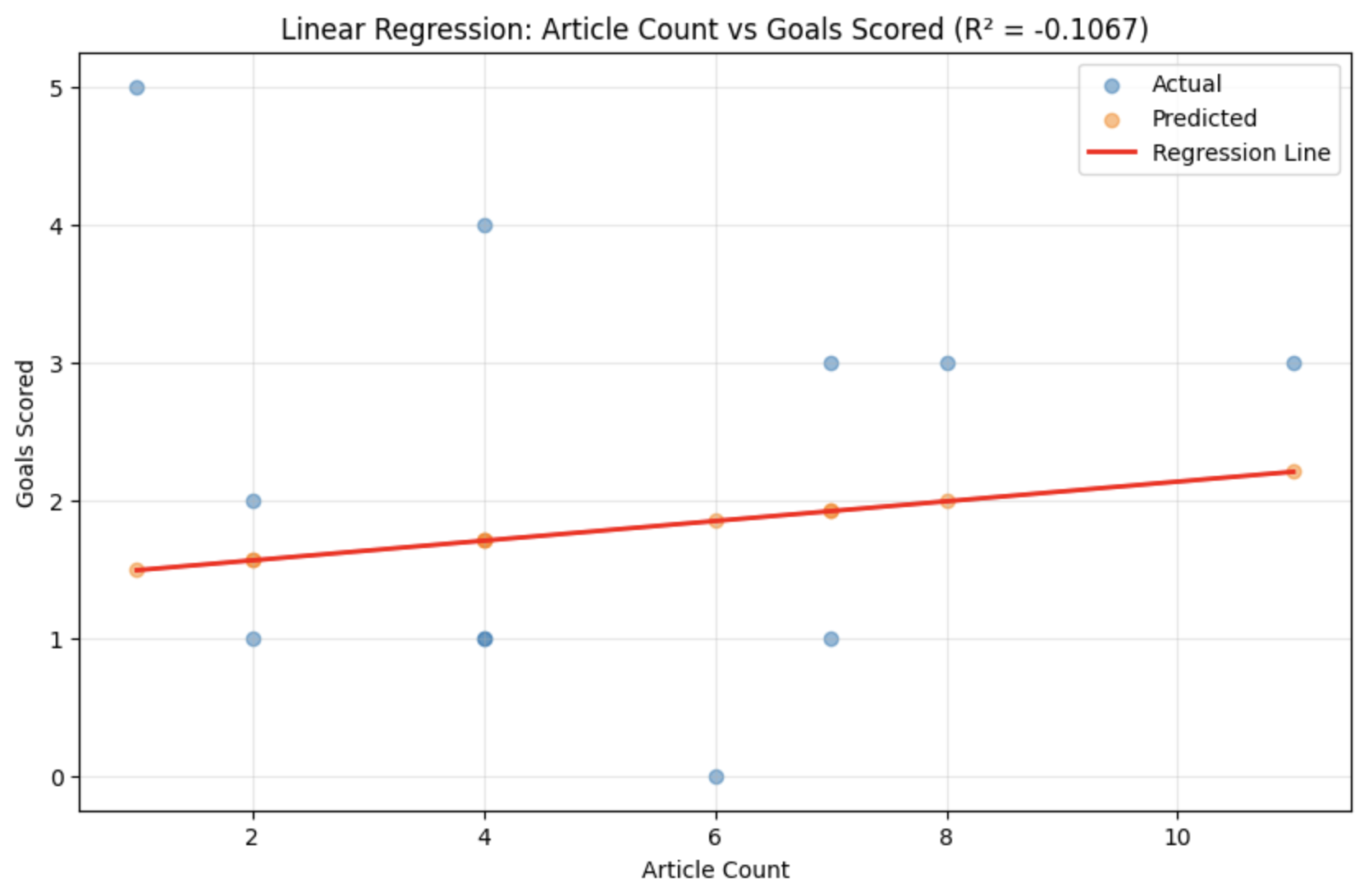
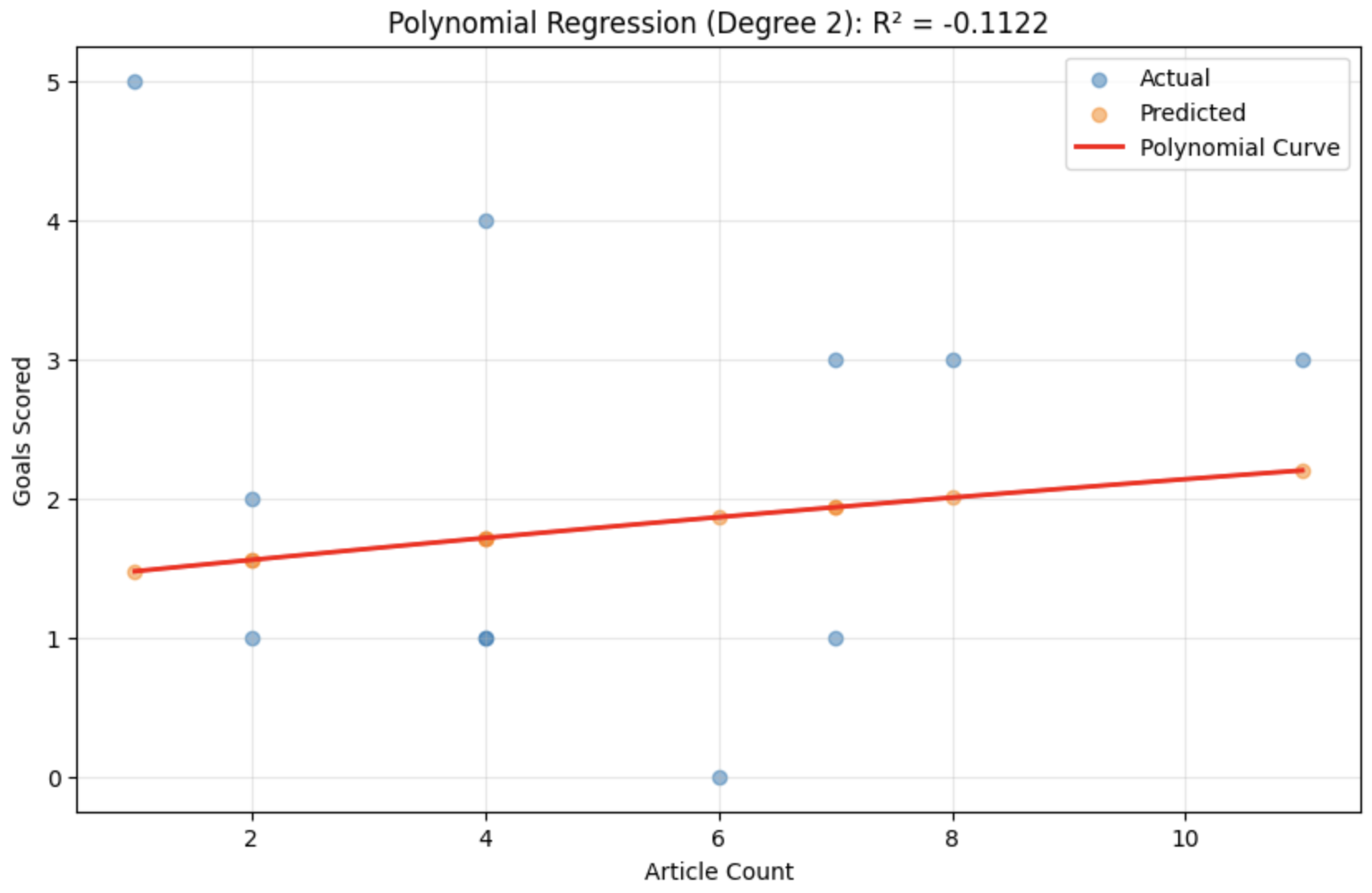
results
Both models performed worse than a naive baseline (predicting mean goals for every match). The negative R² scores definitively show that article count alone has no predictive power for team performance.
future work
ethical considerations
If a strong relationship existed, it could imply media coverage affects player performance and raise suspicious questions about whether the competition was fair before the game even started. An unfair loop of rich and popular teams staying rich and popular, poorer and unpopular but talented teams staying where they are.
Additionally, using article counts disadvantages smaller clubs with less media presence, potentially making predictions less accurate for them regardless of actual performance quality.
construction
Built as a DS3000 (Foundations of Data Science) final project at Northeastern. The codebase spans three Jupyter notebooks handling scraping, cleaning, and modeling separately.
setup_driver() initializes headless Chrome,
scrape_team_fixtures() extracts tables per team, outputs 30+ team-specific DataFrames.
get_guardian_articles() handles making the pages,
get_article_data() parses JSON responses into flat dictionaries.
pd.merge() joins article counts to matches on composite keys.
LinearRegression and
PolynomialFeatures with manual train/test splits and MSE/R² evaluation.
Source? This project was built collaboratively with William Hon, Kinsey Bellerose, and Zaid Jilla. The notebooks demonstrate the full data science pipeline from web scraping through statistical modeling and interpretation.